2020-2021数据挖掘技术试题B答案
运城学院数学与信息技术学院
2020-2021学年第二学期期末考试
《数据挖掘技术》试题(B)参考答案及评分标准
适用范围:数据科学与大数据技术1806 命题人:王鹏岭
审核人:
2020-2021学年第二学期期末考试
《数据挖掘技术》试题(B)参考答案及评分标准
适用范围:数据科学与大数据技术1806 命题人:王鹏岭
审核人:
一、选择题 (每题2分,共20分)
1.B 2.C 3.D 4.C 5.C 6.B. 7.C 8.A 9.C 10. D
二、判断题(每题2分,计16分)
1.对 2.错 3.对 4.错 5. 错 6. 对 7. 错 8. 错
三、问答题(6个小题,每小题6分,共36分)
1. 答:1确定挖掘对象 2准备数据 3建立模型
4数据挖掘 5结果分析 6知识应用
2.答:忽略该记录;去掉属性;手工填写空缺值;使用默认值;使用属性平均值;使用同类样本平均值;预测最可能的值。
3.答:①商业:帮助市场分析人员从客户基本库中发现不同的客户群,并且用不同的购买模式描述不同客户群的特征。
②生物学:推导植物或动物的分类,对基于进行分类,获得对种群中固有结构的认识。
③WEB文档分类④其他:如地球观测数据库中相似地区的确定;各类保险投保人的分组一个城市中不同类型、价值、地理位置房子的分组等。
⑤聚类分析还可作为其他数据挖掘算法的预处理:即先进行聚类,然后再进行分类等其他的数据挖掘。聚类分析是一种数据简化技术,它把基于相似数据特征的变量或个案组合在一起。
4.答:分类规则的挖掘方法通常有:决策树法、贝叶斯法、人工神经网络法、粗糙集法和遗传算法。分类的过程包括2步:首先在已知训练数据集上,根据属性特征,为每一种类别找到一个合理的描述或模型,即分类规则;然后根据规则对新数据进行分类。
5. 答:混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。
分类评估指标中定义的一些符号含义:
TP(True Positive): 将正类预测为正类数,真实为0,预测为0
FN(False Negative):将正类预测为负类数,真实为0,预测为1
FP(False Positive):将负类预测为正类数,真实为1,预测为0
TN(True Negative): 将负类预测为负类数,真实为1,预测为1
6. 答:支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
四、算法题 (共1题, 共13分)
解:用A代表挂科,B代表喝酒,C代表逛街,D代表学习,给出的8个样本中有4个挂科的,所以P(A=0)=4/8=1/2, P(A=1)=1/2;同理,P(B=1)=3/8, P(B=0)=5/8,P(A^B)=2/8,(喝酒且挂科
P(A^D)=1/8,(学习并且挂科了)
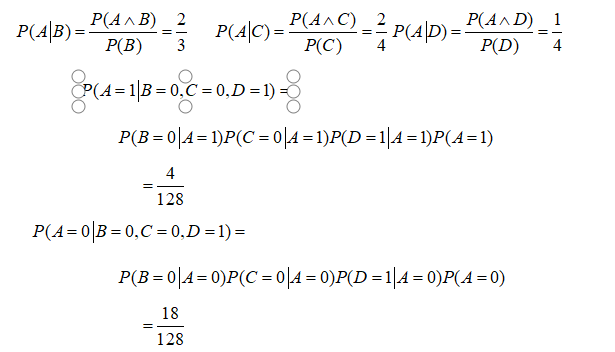
可得考试没有挂科的概率更大
五、应用题(共1题, 共15分)
答:
1.B 2.C 3.D 4.C 5.C 6.B. 7.C 8.A 9.C 10. D
二、判断题(每题2分,计16分)
1.对 2.错 3.对 4.错 5. 错 6. 对 7. 错 8. 错
三、问答题(6个小题,每小题6分,共36分)
1. 答:1确定挖掘对象 2准备数据 3建立模型
4数据挖掘 5结果分析 6知识应用
2.答:忽略该记录;去掉属性;手工填写空缺值;使用默认值;使用属性平均值;使用同类样本平均值;预测最可能的值。
3.答:①商业:帮助市场分析人员从客户基本库中发现不同的客户群,并且用不同的购买模式描述不同客户群的特征。
②生物学:推导植物或动物的分类,对基于进行分类,获得对种群中固有结构的认识。
③WEB文档分类④其他:如地球观测数据库中相似地区的确定;各类保险投保人的分组一个城市中不同类型、价值、地理位置房子的分组等。
⑤聚类分析还可作为其他数据挖掘算法的预处理:即先进行聚类,然后再进行分类等其他的数据挖掘。聚类分析是一种数据简化技术,它把基于相似数据特征的变量或个案组合在一起。
4.答:分类规则的挖掘方法通常有:决策树法、贝叶斯法、人工神经网络法、粗糙集法和遗传算法。分类的过程包括2步:首先在已知训练数据集上,根据属性特征,为每一种类别找到一个合理的描述或模型,即分类规则;然后根据规则对新数据进行分类。
5. 答:混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。
分类评估指标中定义的一些符号含义:
TP(True Positive): 将正类预测为正类数,真实为0,预测为0
FN(False Negative):将正类预测为负类数,真实为0,预测为1
FP(False Positive):将负类预测为正类数,真实为1,预测为0
TN(True Negative): 将负类预测为负类数,真实为1,预测为1
6. 答:支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
四、算法题 (共1题, 共13分)
解:用A代表挂科,B代表喝酒,C代表逛街,D代表学习,给出的8个样本中有4个挂科的,所以P(A=0)=4/8=1/2, P(A=1)=1/2;同理,P(B=1)=3/8, P(B=0)=5/8,P(A^B)=2/8,(喝酒且挂科
P(A^D)=1/8,(学习并且挂科了)
可得考试没有挂科的概率更大
五、应用题(共1题, 共15分)
答:
| 一阶项目集 | 支持度 |
| a | 5 |
| b | 4 |
| c | 2 |
| d | 5 |
| e | 3 |
| f | 4 |
| g | 6 |
| 一阶频繁集 | 支持度 |
| a | 5 |
| b | 4 |
| d | 5 |
| f | 4 |
| g | 6 |
| 二阶候选集 | 支持度 |
| ab | 3 |
| ad | 4 |
| af | 2 |
| ag | 5 |
| bd | 3 |
| bf | 1 |
| bg | 3 |
| df | 3 |
| dg | 4 |
| fg | 3 |
| 二阶频繁集 | 支持度 |
| ad | 4 |
| ag | 5 |
| dg | 4 |
| 三阶候选集 | 支持度 |
| adg | 4 |