2020-2021第二学期数据挖掘技术B题
运城学院数学与信息技术学院
2020-2021学年第二学期期末考试
数据挖掘技术 试题(B)
适用范围:数据科学与大数据技术1806 命题人:王鹏岭
审核人:
2020-2021学年第二学期期末考试
数据挖掘技术 试题(B)
适用范围:数据科学与大数据技术1806 命题人:王鹏岭
审核人:
一、 选择题(每题2分,共20分)
1、当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?
A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链
2、建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?
A.根据内容检 B. 建模描述 C. 预测建模 D. 寻找模式和规则
3、下面哪种不属于数据预处理的方法?
A变量代换 B离散化 C聚集 D估计遗漏值
4、只有非零值才重要的二元属性被称作:
A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性
5、下面选项中属于定量的属性类型是
A 标称 B 序数 C区间 D 相异
6、以下哪些算法是分类算法
A.DBSCAN B. C4.5 C.k-means D.EM
7、可用作数据挖掘分析中的关联规则算法有
A. 决策树、对数回归、关联模式
B. K均值法、SOM神经网络
C. Apriori算法、FP-Tree算法
D. RBF神经网络、K均值法、决策树
8、以下哪些分类方法可以较好地避免样本的不平衡问题,
A,KNN B,SVM C,Bayes D,神经网络
9、关联规则的评价指标是:
A. 均方误差、均方根误差 B. Kappa统计、显着性检验
C. 支持度、置信度 D. 平均绝对误差、相对误差
10、下列有关Web挖掘的叙述不正确的是
A.Web挖掘指从WWW的资源和行为中抽取感兴趣的、有用的模式 和隐含的信息
B.Web挖掘分为Web内容挖掘、Web结构挖掘和Web使用记录的
C.Web结构挖掘是从WWW的组织结构和链接关系中挖掘知识
D.Web内容挖掘是从WWW的访问记录中抽取感兴趣的模式
二、判断题 (共8小题, 每小题2分,共16分)
1、数据取样时,除了要求抽样时严把质量关外,还要求抽样数据必须在足够范围内有代表性.
2、数据分类由两步过程组成:第一步,建立一个聚类模型,描述指定的数据类集或概念集;第二步,使用模型进行分类.
3、数据挖掘的主要任务是从数据中发现潜在的规则,从而能更好的完成描述数据、预测数据等任务.
4、在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差.
5、对于SVM分类算法,待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果有影响.
6、神经网络对噪音数据具有高承受能力,并能对未经过训练的数据具有分类能力,但其需要很长的训练时间,因而对于有足够长训练时间的应用更合适.
7、具有较高的支持度的项集具有较高的置信度.
8、先验原理可以表述为:如果一个项集是频繁的,那包含它的所有项集也是频繁的.
三、问答题(5个小题,每小题6分,共36分)
1. 请简述数据挖掘过程.
2. 简述处理空缺值的方法.
3. 举例说明聚类分析的典型应用
4. 分类知识的发现方法主要有哪些?分类过程通常包括哪两个步骤?
5. 请解释混淆矩阵及评估指标.
6. 请解释SVM的算法原理.
四、算法题 (本小题共13分,)
有8个样例.1代表是,0代表否,使用贝叶斯算法,对未知的样本{没喝酒,没逛街,学习了}预测,求出样本挂科的概率.

五、应用题 (共1题,共15分)
某超市数据库抽取出有7个事务数据,最小支持度计数为4
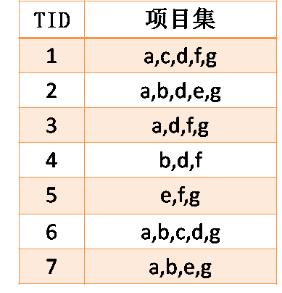
请使用Apriori算法找出所有频繁项集.
1、当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?
A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链
2、建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?
A.根据内容检 B. 建模描述 C. 预测建模 D. 寻找模式和规则
3、下面哪种不属于数据预处理的方法?
A变量代换 B离散化 C聚集 D估计遗漏值
4、只有非零值才重要的二元属性被称作:
A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性
5、下面选项中属于定量的属性类型是
A 标称 B 序数 C区间 D 相异
6、以下哪些算法是分类算法
A.DBSCAN B. C4.5 C.k-means D.EM
7、可用作数据挖掘分析中的关联规则算法有
A. 决策树、对数回归、关联模式
B. K均值法、SOM神经网络
C. Apriori算法、FP-Tree算法
D. RBF神经网络、K均值法、决策树
8、以下哪些分类方法可以较好地避免样本的不平衡问题,
A,KNN B,SVM C,Bayes D,神经网络
9、关联规则的评价指标是:
A. 均方误差、均方根误差 B. Kappa统计、显着性检验
C. 支持度、置信度 D. 平均绝对误差、相对误差
10、下列有关Web挖掘的叙述不正确的是
A.Web挖掘指从WWW的资源和行为中抽取感兴趣的、有用的模式 和隐含的信息
B.Web挖掘分为Web内容挖掘、Web结构挖掘和Web使用记录的
C.Web结构挖掘是从WWW的组织结构和链接关系中挖掘知识
D.Web内容挖掘是从WWW的访问记录中抽取感兴趣的模式
二、判断题 (共8小题, 每小题2分,共16分)
1、数据取样时,除了要求抽样时严把质量关外,还要求抽样数据必须在足够范围内有代表性.
2、数据分类由两步过程组成:第一步,建立一个聚类模型,描述指定的数据类集或概念集;第二步,使用模型进行分类.
3、数据挖掘的主要任务是从数据中发现潜在的规则,从而能更好的完成描述数据、预测数据等任务.
4、在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差.
5、对于SVM分类算法,待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果有影响.
6、神经网络对噪音数据具有高承受能力,并能对未经过训练的数据具有分类能力,但其需要很长的训练时间,因而对于有足够长训练时间的应用更合适.
7、具有较高的支持度的项集具有较高的置信度.
8、先验原理可以表述为:如果一个项集是频繁的,那包含它的所有项集也是频繁的.
三、问答题(5个小题,每小题6分,共36分)
1. 请简述数据挖掘过程.
2. 简述处理空缺值的方法.
3. 举例说明聚类分析的典型应用
4. 分类知识的发现方法主要有哪些?分类过程通常包括哪两个步骤?
5. 请解释混淆矩阵及评估指标.
6. 请解释SVM的算法原理.
四、算法题 (本小题共13分,)
有8个样例.1代表是,0代表否,使用贝叶斯算法,对未知的样本{没喝酒,没逛街,学习了}预测,求出样本挂科的概率.
五、应用题 (共1题,共15分)
某超市数据库抽取出有7个事务数据,最小支持度计数为4
请使用Apriori算法找出所有频繁项集.